原文 链接:https://blog.langchain.com/context-engineering-for-agents/
前言
智能体(Agents)需要上下文(Context)来执行任务。上下文工程是一门艺术与科学的组合体,其核心在于在智能体每一步运行过程(trajectory)中,将最恰当的信息填充进上下文窗口(Context Window)。在这篇文章中,我们通过回顾各种流行的智能体和论文,分解了上下文工程的一些常见策略 —— 写入(write)、选择(select)、压缩(compress)和隔离(isolate)。然后,我们介绍下 LangGraph 是如何设计来支持它们的!此外,也可以在这里观看我们关于上下文工程的视频,对应notion文档链接。
上下文工程 (Context Engineering)
正如 Andrej Karpathy(译者注:OpenAI前科学家) 所说的那样,大语言模型(LLM)就像一种新型的操作系统。LLM 如同中央处理器(CPU),而其上下文窗口则像是随机存取存储器(RAM),充当模型的“工作内存”。就像 RAM 一样,LLM 的上下文窗口处理各种来源的上下文信息的能力是有限的。正如操作系统管理什么内容可以放入 CPU 的 RAM 中一样,我们可以将“上下文工程”视为扮演着类似的角色。Karpathy 对此总结得很好:
[Context engineering is the] ”…delicate art and science of filling the context window with just the right information for the next step.”
[上下文工程是] “…一门精妙的艺术与科学,旨在为下一步操作将最合适的的信息填入上下文窗口。”
LLM 应用中常用的上下文类型
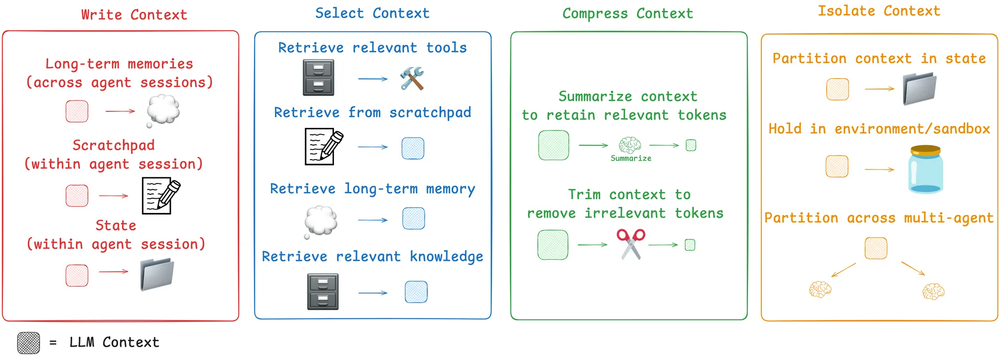
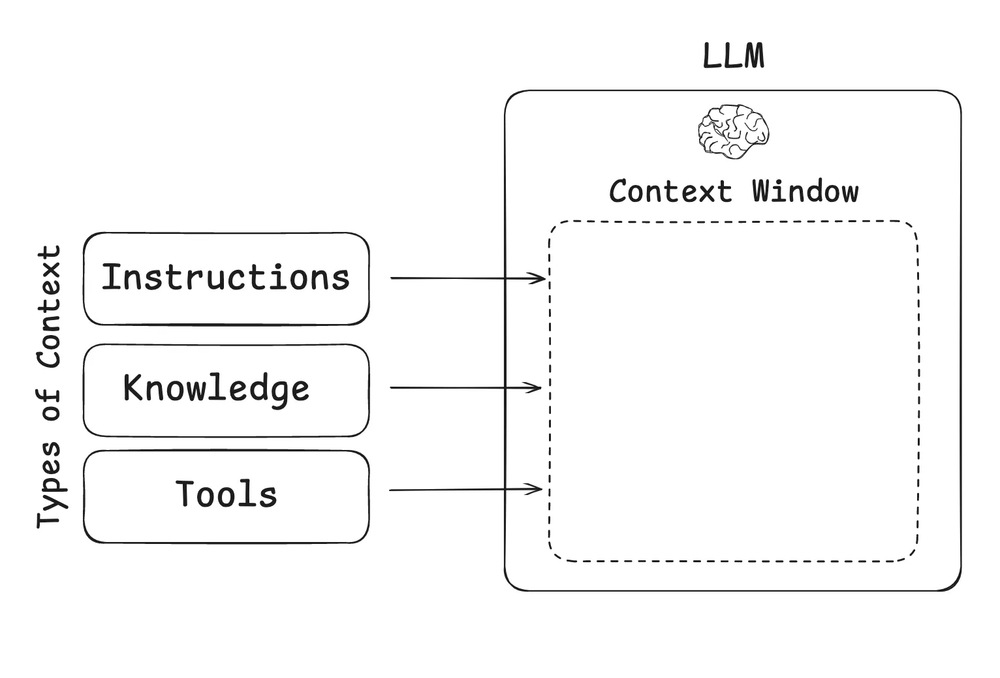
在构建 LLM 应用时,我们需要管理哪些类型的上下文呢?上下文工程就像一把大伞,覆盖不同类型的上下文 :
- 指令 (Instructions) – 提示词(prompts)、记忆(memories)、小样本示例(few-shot examples)、工具描述(tool descriptions)等。
- 知识 (Knowledge) – 事实(facts)、记忆(memories)等。
- 工具 (Tools) – 工具调用的执行结果或反馈(feedback)。
面向智能体的上下文工程
今年,随着 LLM 在推理(reasoning)和工具调用(tool calling)方面能力的提升,行业对对智能体的兴趣也在激增。智能体在长时间运行的任务中,通常会动态地交替着调用LLM和工具。智能体交替调用LLM和工具,正是利用工具的执行结果或反馈来决定下一步要执行的行动。
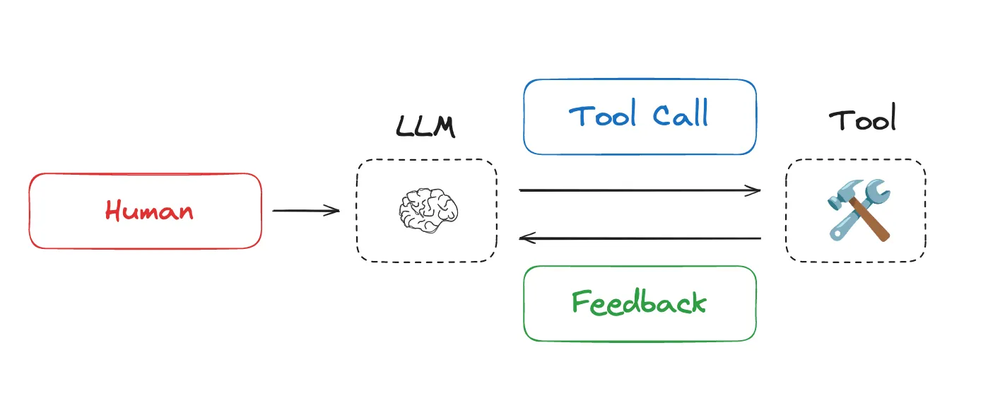
(图注:智能体交替调用 LLM和工具,利用工具反馈来决定下一步动作)
然而,长时间运行的任务和不断累积的工具调用反馈意味着智能体通常会消耗大量token。这可能导致诸多问题:超出上下文窗口的大小限制、导致成本/延迟飙升,或者智能体的执行效果下降。Drew Breunig 很好地总结了长上下文可能导致执行效果出问题的几种具体情况,包括:
- **上下文污染 (Context Poisoning)**:幻觉(hallucination)进入上下文
- **上下文干扰 (Context Distraction)**:上下文信息过多导致淹没模型训练内容
- **上下文混淆 (Context Confusion)**:无关的上下文内容影响模型响应
- **上下文冲突 (Context Clash)**:上下文的不同部分相互矛盾
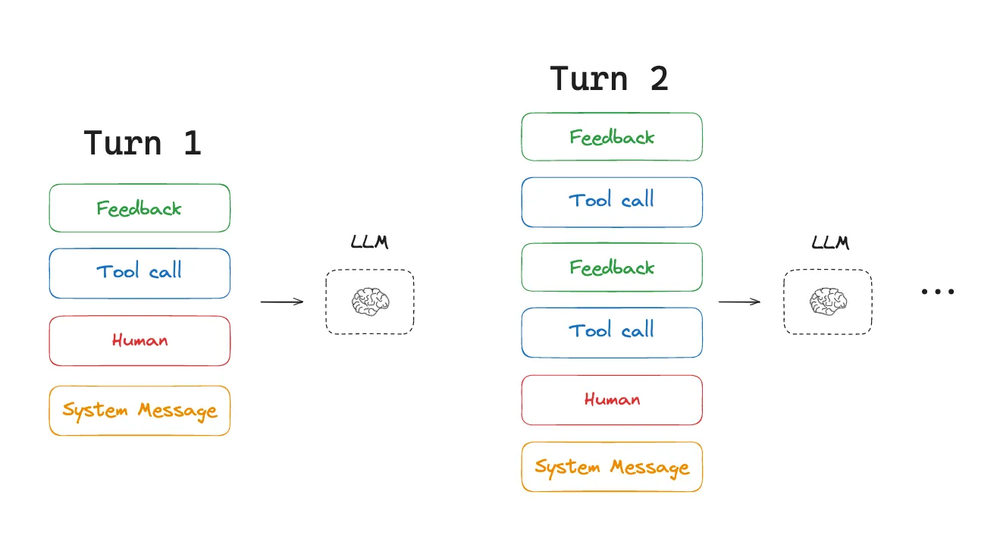
(图注:来自工具调用的上下文在多个智能体轮次中累积)
考虑到这一点,Cognition(一家公司)强调了上下文工程的重要性:
“Context engineering” … is effectively the #1 job of engineers building AI agents.
“上下文工程” … 实际上是构建 AI 智能体的工程师的首要工作。
Anthropic 也清晰地阐述了这一点:
Agents often engage in conversations spanning hundreds of turns, requiring careful context management strategies.
智能体参与的对话通常可能长达几百轮,需要一套谨慎的上下文管理策略。
那么,大家现在是如何应对这一挑战的呢?我们将当前常见的智能体上下文工程策略归纳为四大类 —— 写入(write)、选择(select)、压缩(compress)和隔离(isolate),并通过回顾一些流行的智能体产品和论文为这些类别提供例证。然后,我们解释 LangGraph 是如何设计来支持这些策略的!
(图注:上下文工程的一般类别:写入、选择、压缩、隔离)
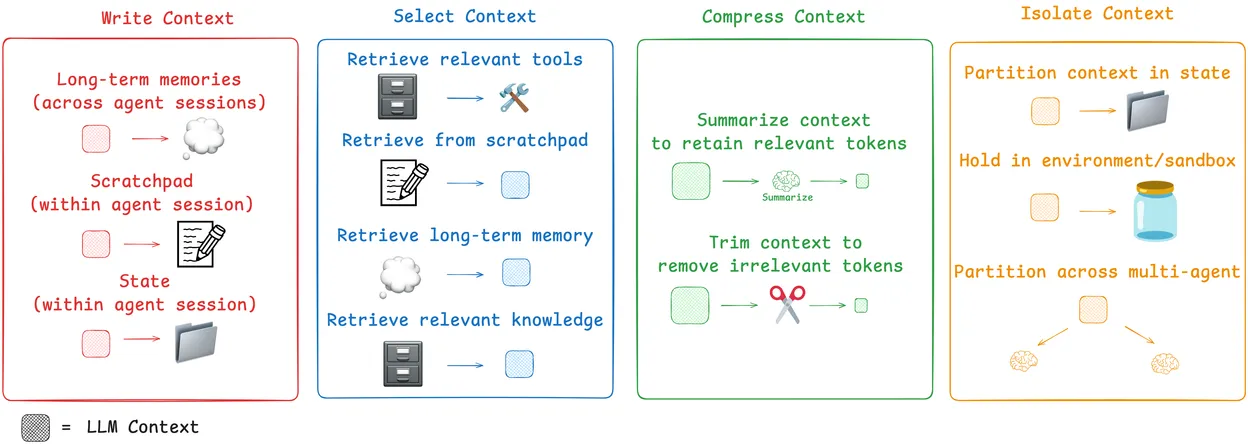
1. 上下文写入 (Write Context)
写入上下文是指将上下文保存在上下文窗口之外,以帮助智能体执行任务。
暂存区 (Scratchpads)
当人类解决问题时,我们会做笔记并记录未来相关任务所需的信息。智能体也在具备这些能力!通过“暂存区”做笔记是一种在智能体执行任务时保存信息的方法。其核心思想是将信息保存在上下文窗口之外,以便智能体在需要时可以获取。Anthropic 的多智能体研究提供了一个清晰的例子:
LeadResearcher(主研究员智能体)首先思考实现方案,并将生成的方案保存到 Memory(记忆)中以持久化保存上下文,因为如果上下文窗口超过 200,000 个令牌,它将被截断,而保留计划非常重要。
暂存区可以通过不同的方式实现。它可以是一个简单的将内容写入文件的工具调用,也可以是在会话期间持续存在的运行时状态对象(runtime state object)中的一个字段。无论哪种方式,暂存区都让智能体能够保存有用的信息来帮助完成任务。
记忆 (Memories)
暂存区帮助智能体在给定的会话(或线程thread)内完成任务,但有时智能体需要跨多个会话记住某些信息!Reflexion 论文引入了在每次智能体轮次后进行“反思”(reflection)并重用这些自我生成的记忆的概念。Generative Agents(生成式智能体)论文则创建了一个定期从智能体过去的内容中合成的记忆。
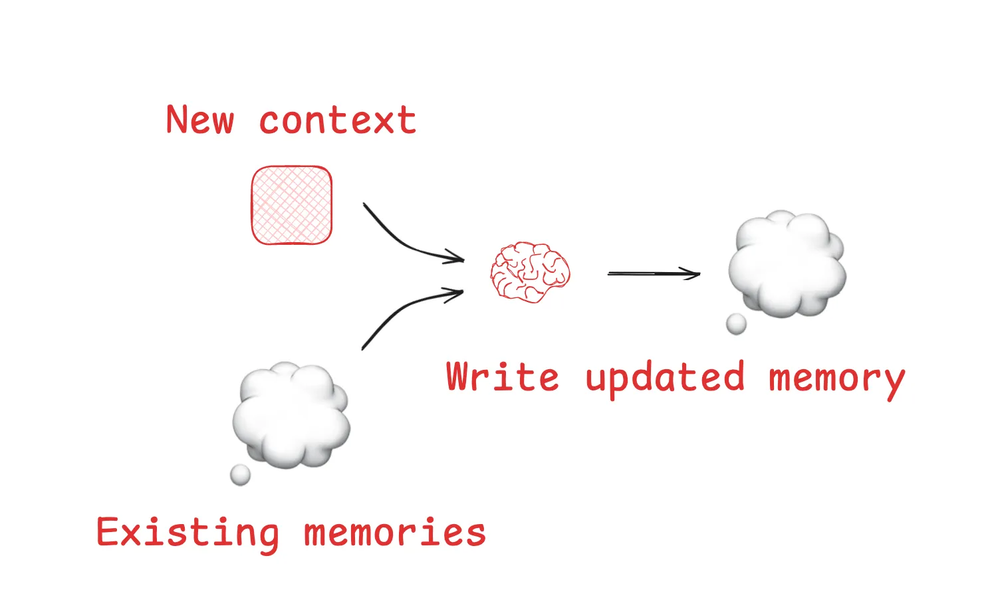
(图注:LLM 可用于更新或创建记忆)
这些概念已经融入到 ChatGPT、Cursor 和 Windsurf 等流行产品中,它们都具备基于用户-智能体交互自动生成长期记忆的机制,这些记忆可以跨会话持久化保存。
2. 上下文选择 (Select Context)
选择上下文是指将上下文拉到上下文窗口里,来帮助智能体执行任务。
暂存区(Scratchpad)
从暂存区选择上下文的机制取决于暂存区的实现方式。如果它是一个工具,那么智能体只需通过工具调用即可读取里面的内容。如果它是智能体运行时状态(State)的一部分,那么开发者可以选择在每个执行步骤中向智能体暴露哪些状态信息。这为在后续轮次中将暂存区上下文暴露给 LLM 提供了细粒度的控制。
记忆
如果智能体有能力保存记忆,它们也需要有能力选择与当前任务相关的记忆。这可能出于几个原因:智能体可能会选择少样本示例(情景记忆 episodic **memories**)作为所期望行为的示例,业可以选择指令(程序记忆 procedural memories) 来引导行为,或者选择事实(语义记忆 semantic memories)作为任务相关的背景知识。

一个难点是如何确保选择到相关的记忆。一些流行的智能体只是简单地使用一组特定的文件,这些文件总是被提取到上下文里。例如,许多代码智能体使用特定文件来保存指令(“程序(procedural)”记忆),或者在某些情况下保存示例(“情景(episodic)”记忆)。Claude Code 使用 CLAUDE.md 文件。Cursor 和 Windsurf 使用规则文件。
但是,如果智能体存储了大量(collection事实和/或关系(例如,语义记忆),选择就变得困难了。ChatGPT 就是一个很好的例子,它存储了一个庞大的用户特定记忆集合并从中进行选择。
嵌入(Embeddings)和/或知识图谱(**knowledge** **graphs**)常用于辅助记忆索引和选择。尽管如此,记忆选择仍然具有挑战性。在 AIEngineer 世界博览会(AIEngineer World’s Fair)上,Simon Willison 分享了一个记忆选择错误的例子:ChatGPT 从他的记忆中获取了他的位置信息,并将其非预期地注入到一个请求生成的图像中。这种非预期或不必要的记忆检索可能会让一些用户觉得上下文窗口“不再属于他们自己”!
工具 (Tools)
智能体使用工具,但如果提供过多的工具,它们可能会变得不堪重负。这通常是因为工具描述相互重叠,导致模型在决定使用哪个工具时产生混淆。一种方法是对工具描述采用RAG(检索增强生成)方案,只为某一特定任务获取最相关的工具。最近的一些论文表明,这可以将工具选择的准确性提高 3 倍。
知识 (Knowledge)
RAG 是一个很大的主题,它可能是上下文工程的核心挑战之一。代码智能体是大规模生产场景中 RAG 的最佳范例之一。Windsurf 的 Varun 很好地捕捉了其中的一些挑战:
Indexing code ≠ context retrieval … [We are doing indexing & embedding search … [with] AST parsing code and chunking along semantically meaningful boundaries … embedding search becomes unreliable as a retrieval heuristic as the size of the codebase grows … we must rely on a combination of techniques like grep/file search, knowledge graph based retrieval, and … a re-ranking step where [context] is ranked in order of relevance.
索引代码 ≠ 上下文检索 … [我们正在做] 索引和嵌入搜索 … [利用] AST 解析代码并按语义上有意义的边界进行分块 … 随着代码库规模的增长,嵌入搜索作为启发式检索方法变得不可靠 … 我们必须依赖多种技术的组合,如 grep/文件搜索、基于知识图谱的检索 … 以及一个对[context 上下文]按相关性排序的重排(re-ranking)环节。
3. 上下文压缩 (Compressing Context)**
压缩上下文涉及仅保留执行任务所需的token。
上下文摘要 (Context Summarization)
智能体交互可能跨越数百轮,并且频繁调用工具而产生大量的token内容。摘要(Summarization)是解决这些难题的常见方法之一。如果大家使用过 Claude Code,就应该已经见过这种操作。当上下文窗口使用率超过 95% 时,Claude Code 会运行“自动压缩”(auto-compact),它会对用户-智能体交互的完整轨迹生成摘要。这种对智能体轨迹的压缩可以使用各种策略,例如递归摘要或分层摘要。
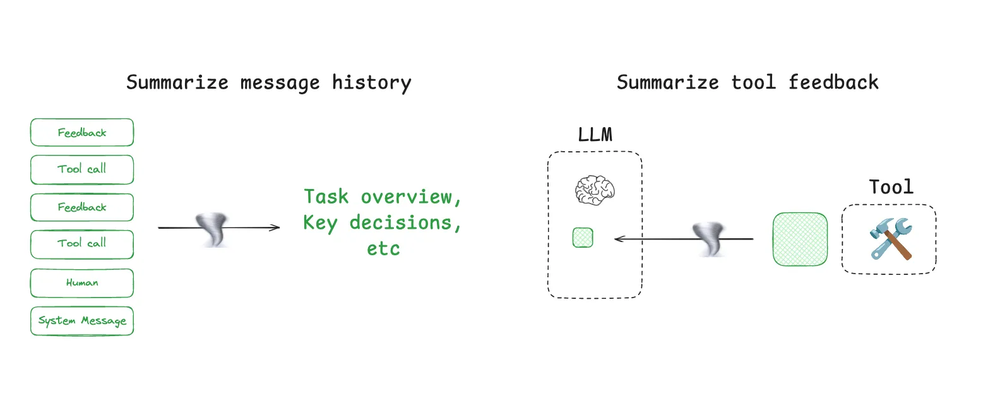
图注:可以执行摘要生成操作的地方
在智能体设计的特定节点添加摘要也很有用。例如,它可以用于后处理某些工具调用(例如,令牌密集型的搜索工具)。第二个例子是,Cognition 提到在智能体-智能体边界处使用摘要,以减少知识传递过程中的令牌消耗。如果要捕获特定的事件或决策,摘要生成操作会是一个挑战。Cognition 为此使用了微调模型,这凸显了这一步可能需要投入多少工作量。
上下文修剪 (Context Trimming)
摘要通常使用 LLM 来提炼最相关的上下文片段,而修剪则通常是通过过滤或如 Drew Breunig 所指出的“剪枝”(prune)来实现。这可以使用硬编码的启发式方法,例如从列表中删除较早的消息。Drew 还提到了 Provence,一个为问答任务训练的上下文修剪器。
4. 上下文隔离 (Isolating Context)**
隔离上下文涉及将其拆分以帮助智能体执行任务。
多智能体 (Multi-agent)
隔离上下文最流行的方法之一是将其分散到子智能体(sub-agents)中。OpenAI 的 Swarm 库的一个动机就是关注点分离(separation of concerns),即一个智能体团队可以处理特定的子任务。每个智能体都有特定的工具集、指令和自己的上下文窗口。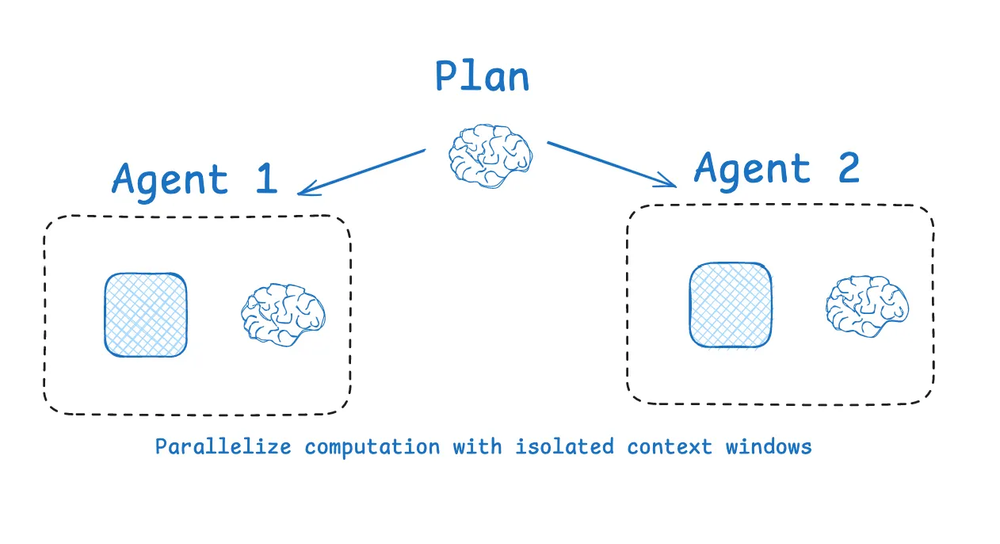
(图注:将上下文分割到多个智能体)
Anthropic 的多智能体研究员multi-agent researcher为此提供了论据:多个具有隔离上下文的子智能体性能优于单一智能体,这在很大程度上是因为每个子智能体的上下文窗口可以被分配来处理更窄的子任务。正如该博客所说:
[Subagents operate] in parallel with their own context windows, exploring different aspects of the question simultaneously.
[子智能体] 在其各自的上下文窗口中并行运行,同时探索问题的不同方面。
当然,多智能体也面临挑战,包括令牌使用(例如,Anthropic 报告称其令牌消耗可能高达聊天的 15 倍)、需要精心设计提示词来规划子智能体的工作,以及协调子智能体。
利用环境进行上下文隔离 (Context Isolation with Environments)
HuggingFace 的深度研究员 deep researcher展示了一个有趣的上下文隔离例子。大多数智能体使用工具调用 API,这些agent 返回 JSON 对象(工具参数),可以传递给工具(例如搜索 API)以获取工具执行结果或反馈(例如搜索结果),HuggingFace 使用一个代码智能体(CodeAgent),它会输出包含所需要的工具调用的代码。该代码随后在沙箱(sandbox)中运行。工具调用所选定的上下文(例如返回值)之后会被传递回 LLM。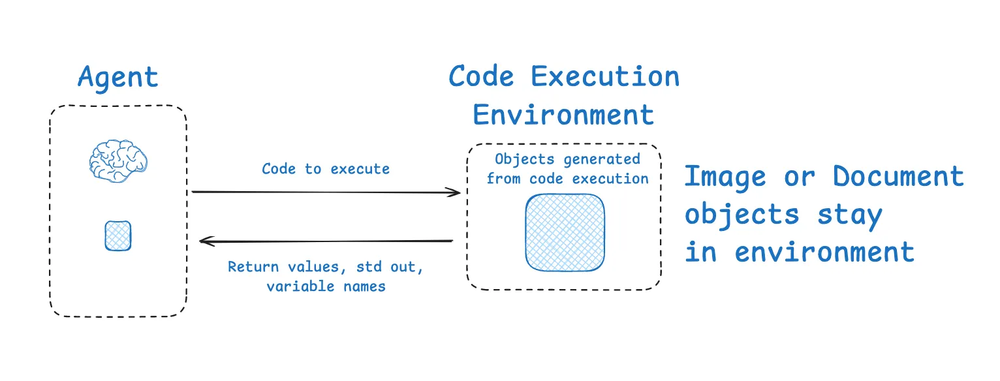
(图注:沙箱可以将上下文与 LLM 隔离。)
这使得上下文在沙箱环境中与 LLM 隔离。Hugging Face 指出,这对于隔离令牌密集型对象特别有用:
[Code Agents allow for] a better handling of state … Need to store this image / audio / other for later use? No problem, just assign it as a variable in your state and you [use it later].
[代码智能体允许] 更好地处理状态 … 需要存储这张图片/音频/其他内容供以后使用?没问题,只需将其作为变量分配到你的状态中,你[就可以在以后使用它]。
状态 (State)
值得一提的是,智能体的运行时状态对象(runtime state object)也是一个隔离上下文的好方法。它可以达到与沙箱相同的目的。状态对象可以设计一个模式(schema),其中包含可以写入上下文的字段。schema中的一个字段(例如 messages)可以在智能体的每一轮中暴露给 LLM,但schema 可以在其他字段中隔离信息,以便更选择性地使用。
使用 LangSmith/ LangGraph 实现上下文工程
那么,如何使用这些思想呢?在开始之前,有两个基础部分非常有帮助。首先,确保能查看数据并跟踪智能体的token使用情况:这有助于确定应用上下文工程的最佳着力点。LangSmith 非常适用于智能体追踪/可观察性(tracing/observability),是完成此任务的绝佳方式。其次,务必拥有一种简单的方法来测试上下文工程是否损害或改进了智能体性能,LangSmith 支持智能体评估(agent evaluation),可用于测试任何上下文工程工作的影响。
上下文写入 (Write context)
LangGraph 在设计时考虑了thread作用范围(thread-scoped)
(短期short-term记忆)和长期记忆(long-term memory)。
短期记忆 使用检查点机制(checkpointing)在智能体运行轨迹的所有步骤中持久化存储智能体状态(agent state)。这作为一个“暂存区”极其有用,允许你将信息写入状态,并在智能体轨迹的任何阶段获取它。
LangGraph的长期记忆:允许你在与智能体的多次会话中持久化保存上下文。它非常灵活,既可以保存到一小组的文件(例如用户配置文件或规则)中,也可以保存成更大的记忆集合 collections 。此外,LangMem 提供了一套丰富的实用抽象来辅助 LangGraph 的长期记忆管理。
上下文选择 (Select context)
在 LangGraph 智能体的每个节点(步骤)中,用户都可以获取状态 state。这样就可以对智能体的每个步骤中向 LLM 填充哪些上下文提供细粒度的控制。
此外,LangGraph 的长期记忆在每个节点内都是可访问的,并支持各种类型的检索(例如,获取文件以及对记忆集合进行基于嵌入的检索)。关于长期记忆的概述,请参阅我们的 Deeplearning.ai 课程。对于应用于特定智能体的记忆入口点,请参阅我们的 Ambient Agents 课程。该课程展示了如何在一个可以管理你的电子邮件并从你的反馈中学习的长运行智能体中使用 LangGraph 记忆。
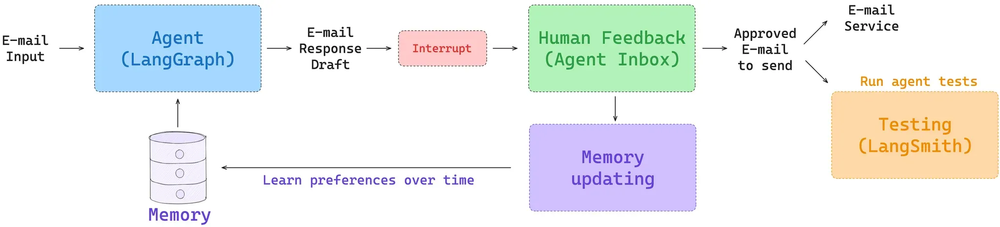
(图注:具有用户反馈和长期记忆的邮件智能体)
对于工具选择,LangGraph 的 Bigtool 库 是一个很好的方式,可以在处理大量工具时基于工具描述进行语义检索(semantic search)。这有助于为特定任务选择最相关的工具。
最后,我们有几个教程和视频,展示了如何将各种类型的 RAG 与 LangGraph 结合使用。
上下文压缩 (Compressing context)
由于 LangGraph 是一个底层的编排框架,你可以将智能体编排设计为一组节点(nodes),定义每个节点内的逻辑以及在它们之间传递的状态对象(state object)。这种控制提供了几种压缩上下文的方法。
一种常见的方法是使用消息列表(message list)作为你的智能体状态,并使用一些内置的实用工具定期对其生成摘要或修剪。
但是,用户还可以通过各种方法来为智能体的工具调用或其他工作阶段增加后处理逻辑。可以在特定节点添加摘要生成节点,也可以给工具调用节点添加摘要生成逻辑,以压缩特定工具调用的输出结果。
上下文隔离 (Isolating context)
LangGraph 围绕状态 State对象设计,允许用户指定状态格式(state schema)并在智能体的各个步骤中访问状态 State。
状态隔离:例如,用户可以将来自工具调用的上下文存储在状态的某些字段中,将它们与 LLM 隔离,直到需要该上下文时才暴露。
沙箱:除了状态 state,LangGraph 支持使用沙箱进行上下文隔离。请参阅此代码库查看使用 E2B 沙箱进行工具调用的 LangGraph 智能体示例。观看此视频查看使用 Pyodide 进行沙箱化并持久化状态的例子。
多智能体:LangGraph 对构建多智能体架构有很好的支持,例如 supervisor 和 swarm 库。用户可以观看这些视频1、视频2、视频3以获取有关在 LangGraph 中使用多智能体的更多细节。
结论
上下文工程正成为智能体构建者需要掌握的一门技术。在本文中,我们涵盖了许多当今流行的智能体中常见的几种模式:
- 写入上下文 (Writing context) - 将其保存在上下文窗口之外,以帮助智能体执行任务。
- 选择上下文 (Selecting context) - 将其拉入上下文窗口,以帮助智能体执行任务。
- 压缩上下文 (Compressing context) - 仅保留执行任务所需的token。
- 隔离上下文 (Isolating context) - 将其拆分,以帮助智能体执行任务。
LangGraph 使得实现上面的策略变得很容易,而 LangSmith 则提供了一种简单的方法来测试你的智能体并跟踪上下文使用情况。LangGraph 和 LangSmith 共同构成了一个良性反馈循环,用于识别应用上下文工程的最佳机会、实施它、测试它并不断迭代优化。