
开源项目推荐
该项目具备不到500毫秒的延迟,并且可以在本地GPU上运行。
该项目是一个模块化的语音转语音流水线,该流水线由四个主要部分组成:语音活动检测(VAD)、语音转文字(STT)、语言模型(LM)和文本到语音(TTS)。VAD使用Silero VAD v5;STT使用Whisper模型;LM可以选择HuggingFace上的任何指令模型;TTS则才用了Parler-TTS。
每个组件都是可替换的,这使得系统可以根据需求灵活地进行调整和优化。
通过使用Torch Compile,可以显著提高Whisper和Parler-TTS的性能,减少延迟,提升用户体验。
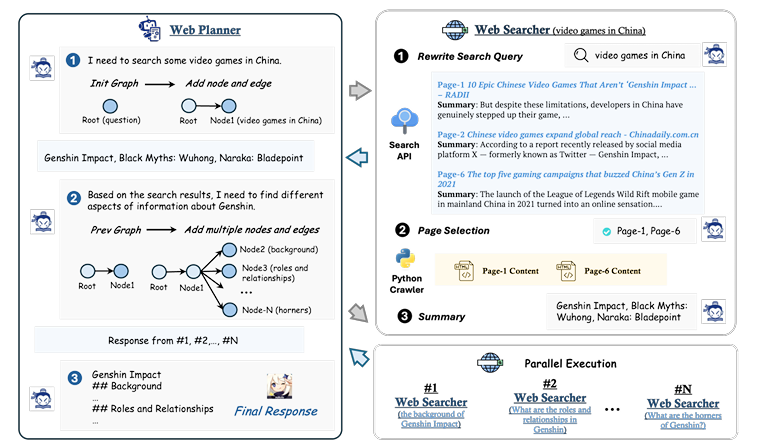
MindSearch是上海人工智能实验室联合研发团队推出的开源人工智能搜索框架,集大规模信息收集和组织能力于一身。
利用 InternLM2.5 7B 对话模型,MindSearch 可以在 3 分钟内从 300 多个网页中收集有效信息,完成人类通常需要 3 小时才能完成的任务。它采用多代理框架模拟人类思维,先规划后搜索,提高了信息的准确性和完整性。
它由两个主要组件组成:WebPlanner 和 WebSearcher。WebPlanner 将用户的问题分解为部分搜索任务,并根据搜索结果确定下一步。这一过程使用图结构表示。同时,WebSearcher 执行分层信息搜索,以收集相关信息。
Sensei,开源的、类似perplexity的AI驱动搜索引擎,利用LLM提供智能搜索和回答
支持本地和云端部署,适用于需要高效搜索和问答功能的各种应用场景
Demo地址
阿里发布,可以处理长图片序列,可以应用于比如需要结合图文知识、混合图文内容和处理长视频场景中
特点:
1、长序列处理能力: 可以有效处理和理解包含多个图像的长序列,比如多图像推理、长视频理解和多文档问答等
2、高效的视觉-语言语义对齐: mPLUG-Owl3能够理解图像和文本之间的关系,并根据文本语义从图像序列中提取相关信息
3、干扰抵抗能力: 可以在干扰环境下保持关注,比如在包含大量无关图像的序列中,仍然能够准确地识别和理解目标图像
4、多模态能力:可以处理各种多模态任务,视觉问答、图像生成、图像描述、多模态对话等
Agent Zero是一个个性化,可以有机发展的AI框架,不是为特定任务预设的代理框架,随着使用反馈可以不断成长和学习,有如下特点:
- 1、通用助手:Agent Zero是一个通用AI 助手,可以用于不同任务,具有持久记忆能力,可以记住先前的解决方案、代码、事实和指令
- 2、计算机作为工具:Agent Zero使用操作系统和终端执行任务,可以编写自己的代码并使用终端来创建和使用其需要的工具
- 3、多代理协作:支持多代理协作,将复杂的任务分解成多个子任务,由不同的代理分别完成
- 4、实时交互:支持实时查看其输出,并随时干预
- 5、支持高度定制和扩展,支持基于提示进行交互
Perplexity Pages 开源平替!可浏览网络生成长达「几万字」的长篇文章/研究论文,还带引用!
Pezzo是一个完全基于云的开源LLMOps平台。它可以无缝地观察和监控您的AI操作,排查问题,节省高达90%的成本和延迟,在一个地方协作和管理您的提示,并立即交付AI更改。
msys 开源了 RouteLLM,这是一个用于服务和评估 LLM 路由器的框架,提供 OpenAI 兼容的服务器,支持多种路由策略,能够在保持高质量的同时显著降低成本。
例如一些不难的问题就转给 Mixtral 8x7b 模型来处理,高难度的才会给 GPT-4o,以此降低成本。
RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。最近新增功能有:
- 现在支持用RAG技术实现从自然语言到SQL语句的转换。
- 支持 GraphRAG 启发于 graphrag 和思维导图。
- 支持 Agentic RAG: 基于 Graph 的工作流。
- 支持更多大模型以及算子
本项目旨在通过构建李白知识图谱,结合大模型训练出专业的AI智能体,以生成式对话应用的形式,推动李白文化的普及与推广。
遗憾的是很多资料文档数据并未提供,导致本项目无法进行实际应用。只能作为研究学习使用。
Demo
Emoji 数据 (主要是 Unicode 数据) 整理收集,主要参考了 Unicode® Technical Standard #51 / UNICODE EMOJI (http://unicode.org/reports/tr51/#Major_Sourcesyanfa2024) 中对 Emoji 的数据定义和范围列表,存储于:server/data/emoji-data.txt
Emoji 数据通过 Embedding 模型形成向量数据,模型采用的是 OpenAI / text-embedding-ada-002
是一个开源 Python 库,简化了网络爬虫和数据提取,使其适用于 LLMs和 AI 应用
完全免费且开源
🤖 适合 LLM 的输出格式(JSON、HTML、Markdown) 🌍 支持同时爬取多个 URL
🎨 提取并返回所有媒体标签(图片、音频和视频)
🔗 提取所有外部和内部链接
📚 提取页面的元数据
🔄 支持自定义钩子进行身份验证、设置头部信息以及在爬取前修改页面
🕵️ 用户代理 (User-agent) 自定义
🖼️ 截取页面屏幕截图
📜 在爬取前执行多个自定义 JavaScript 脚本
📚 各种分块策略:基于主题的、正则表达式的、句子分割等
🧠 高级提取策略:余弦聚类、LLM 等
🎯 支持 CSS 选择器
📝 传递指令/关键词以优化提取过程
技术介绍
- 一年多前的老文重温。
What are AI agents and why do they matter?
开发经验
How Document Chunk Overlap Affects a RAG Pipeline
- RAG 分块大小和块重叠在塑造系统性能和生产中的输出质量方面发挥着关键作用。
- 分块大小决定了输入系统的信息粒度
- 分块重叠确保在分块过程中不会丢失上下文关键信息,确保信息流畅性
- RAG 评估方法:
- 使用 RAGAs 框架进行评估,评估指标包括忠实度、相关性、上下文精确度和召回率
- 分块重叠实验结论:
- 发现分块重叠为 30 时性能最佳,超过 30 后响应时间增加,性能提升有限
- 没有通用的最佳值,需要根据具体用例和文本性质来决定,需要平衡响应时间、忠实度和相关性等因素
- 语义分块 (Semantic Chunking) 技术:
- 语义分块考虑句子的语义相似性,可以提高检索质量和响应质量
- 实验显示语义分块略微优于传统分块方法。
一份 RAG 技术的全面指南,分为 4 个主要阶段:
- 预检索和数据索引技术:
- 使用 LLM 增加信息密度
- 应用分层索引检索
- 使用假设问题索引改善检索对称性
- 使用 LLM 删除数据索引中的重复信息
- 测试和优化分块策略
- 检索技术:
- 使用 LLM 优化搜索查询
- 使用假设文档嵌入 (HyDE) 解决查询-文档不对称问题
- 实现查询路由或 RAG 决策模式
- 检索后技术:
- 使用 reranking 优先处理搜索结果
- 使用上下文提示压缩优化搜索结果
- 使用校正 RAG 对检索到的文档进行评分和过滤
- 生成技术:
- 使用思维链提示调整噪音
- 使用 Self-RAG 使系统具有自反性
- 通过微调忽略不相关上下文
- 使用自然语言推理使 LLM 对不相关上下文具有鲁棒性
- 其他潜在改进
- 微调嵌入模型:通过调整嵌入模型来优化性能
- 使用 GraphRAG:将知识图谱引入 RAG 系统
- 使用长上下文 LLM:如 Gemini 1.5 或 GPT-4 128k,以替代传统的分块和检索方法
Embedding Models: From Architecture to Implementation
-吴恩达的视频课程,主要内容:
- 了解词嵌入、句子嵌入和交叉编码器模型;以及如何在 RAG 中使用它们
- 了解 Transformer 模型,特别是 BERT(Transformers 的双向编码器表示)如何在语义搜索系统中进行训练和使用
- 了解句子嵌入的演变并了解双编码器架构是如何形成的
- 使用对比损失来训练双编码器模型,其中一个编码器针对问题进行训练,另一个编码器针对响应进行训练
- 在 RAG 管道中使用单独的编码器进行问答,并了解与使用单个编码器模型相比,它如何影响检索。
课程覆盖RAG, evaluation, applications, fine-tuning 以及prompt engineering
Anthropic的prompt engineering教程
Prompt Compression and Query Optimization
旨在教授如何优化 RAG(Retrieval-Augmented Generation)应用的成本和性能,通过结合传统数据库功能与 MongoDB 的向量搜索能力,
- 向量搜索:用于用户查询的语义匹配。
-使用元数据过滤:通过预过滤和后过滤来缩小搜索结果范围。
-投影:仅选择必要字段以最小化返回的数据量。
-提升:重新排名结果以提高相关性。
-提示压缩:使用小型语言模型压缩上下文,显著减少令牌数量和处理成本。
GraphRAG与llamaindex的结合
视频
GraphRAG_v1
GraphRAG_v2
The GraphRAG Manifesto: Adding Knowledge to GenAI
- Neo4j 发布的《GraphRAG 宣言》!🔥。介绍了 GraphRAG 最全面的技术,包括学习教程,以及端到端的开源技术栈,同时 GraphRAG 在 43 个业务问题中准确性平均提高 3x ⚡️。
扩展阅读
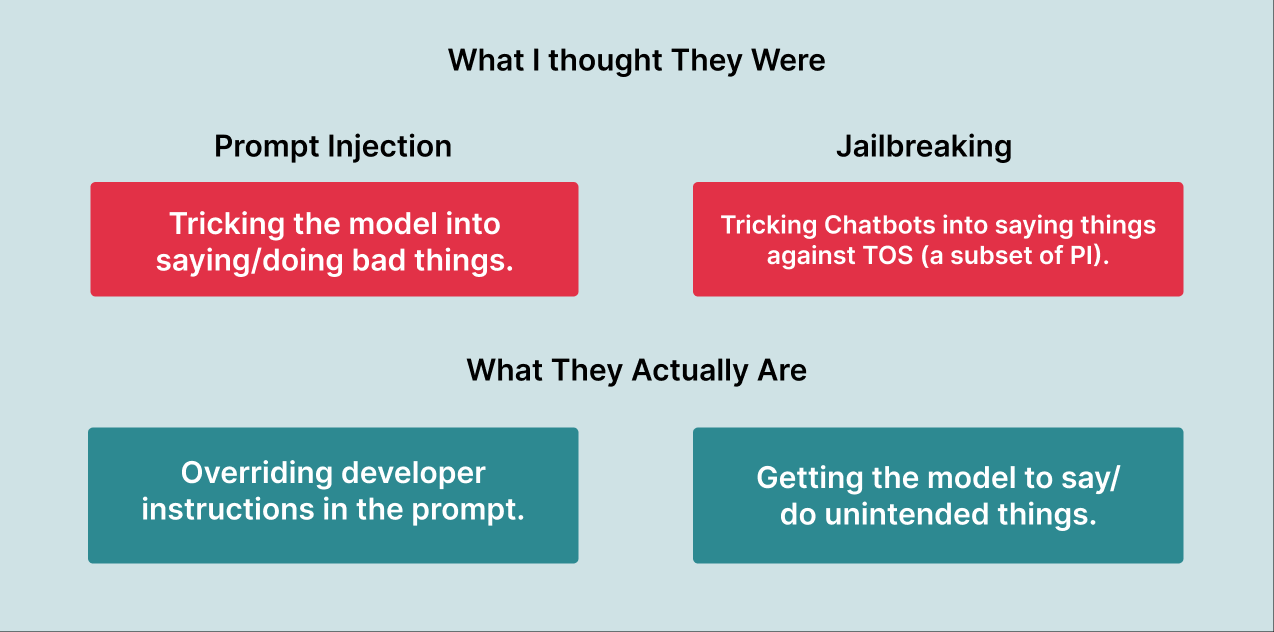
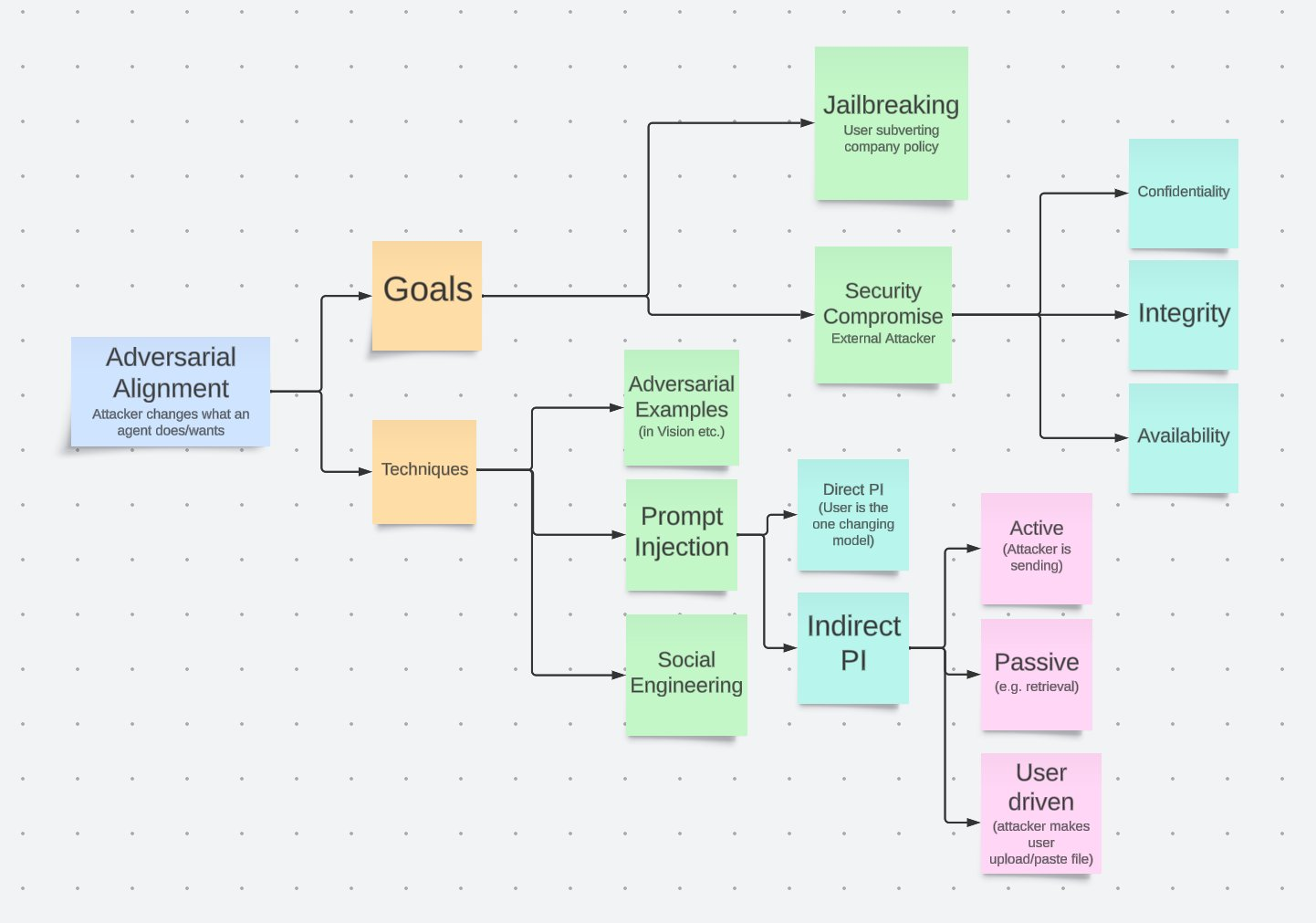
Prompt Injection VS Jailbreaking: What is the difference?
提示词注入是通过不可信的特殊输入覆盖提示词中的原始指令的过程。它是由于生成式 AI 模型无法理解开发者原始指令和用户输入指令之间的区别而导致的架构问题。
在直接提示词注入中,不可信的输入是用户输入,而在间接提示词注入中,这些输入可能来自网站内容或其他“外部来源”。
“越狱”是通过提示词使生成式 AI 模型做或说出未预期的事情的过程。这是一个架构问题或训练问题,因为对抗性提示词极难防止。
Extrinsic Hallucinations in LLMs
完整介绍了 LLM 产生幻觉的原因、检测方法和防止幻觉的方法。
How to Build Your Career in AI
Deeplearning 出品,整理了吴恩达老师对 AI 的关键洞察,尤其是如何在 AI 方向学习和工作,开篇是吴恩达老师很著名的一句话:
“AI is the new electricity. It will transform and improve all areas of human life.” - Andrew Ng