原文 链接:https://www.dbreunig.com/2025/06/22/how-contexts-fail-and-how-to-fix-them.html?ref=blog.lidaxia.io
摘要:
随着前沿模型纷纷支持百万级token的超长上下文窗口,许多人兴奋地认为这将解锁智能体的终极潜力——毕竟,只需将所有工具、文档、指令一股脑塞进提示词,模型就能搞定一切。然而,现实是:过长的上下文不仅不能提升效果,反而可能导致智能体或应用以意想不到的方式崩溃。本文将探讨上下文污染、干扰、混淆和冲突四大问题,揭示长上下文为何成为智能体的双刃剑。
随着前沿模型纷纷突破百万级令牌(Token)的上下文窗口限制,我看到许多讨论都在憧憬长上下文如何成就梦想中的智能体(Agent)。毕竟,窗口足够大,就能把所有可能需要的“配料”——工具说明、文档、指令等等——统统塞进提示词(Prompt),然后放手让模型大展拳脚。
长上下文一度削弱了RAG(检索增强生成)的热度(既然所有文档都能塞进提示词,就不需要在检索文档了!),助长了MCP的炒作(连接所有工具,模型无所不能!),更点燃了人们对智能体的热情。
但残酷的现实是:更长的上下文窗口,并不自动等同于更好的输出结果。过长的上下文反而可能导致你的智能体和应用以意想不到的方式失败。 上下文可能被“污染”,导致注意力分散、内容混淆,甚至相互冲突。这对于依赖上下文来收集信息、综合发现的内容并协调行动的智能体来说,尤其危险。
让我们逐一探讨上下文失控的几种情况,再回顾下如何缓解或彻底规避这些“上下文失败”。
上下文失败(Context Fails)
- 上下文污染 (Context Poisoning): 幻觉(Hallucination)或错误渗入上下文并持续影响。
- 上下文干扰 (Context Distraction): 上下文过长导致模型过度关注上下文本身,忽视预训练知识。
- 上下文混淆 (Context Confusion): 上下文中无关紧要的内容被模型误用,导致低质量输出。
- 上下文冲突 (Context Clash): 上下文中的新信息/工具与原有信息产生直接冲突。
1. 上下文污染:当幻觉渗入上下文
上下文污染是指幻觉或其他错误进入上下文后,被模型反复引用。
DeepMind团队在Gemini 2.5的技术报告中指出了这个问题,我们上周对这篇技术文档做过[拆解分析](https://dbreunig.com/2024/05/17/context-is-everything.html) 。在玩《精灵宝可梦》时,Gemini智能体偶尔会产生幻觉并污染自身上下文:
“一个尤为严重的问题是‘上下文污染’——上下文中的多个部分(目标、摘要)被游戏状态的错误信息‘污染’,这通常需要很长时间才能纠正。结果,模型可能执着于追求不可能或无关的目标。”
如果其上下文中的“目标”部分被污染,智能体就会制定没有意义的策略,并重复执行某些动作,以追求一个根本无法实现的目标。
2. 上下文干扰:当长度成为负担
上下文干扰是指上下文过长,导致模型过度关注上下文内容,反而忽略了预训练阶段学到的知识。
在智能体工作流中,随着模型不断收集信息和累积历史记录,这些不断增长的上下文可能会变得令人分心而不是有所帮助。玩《精灵宝可梦》的Gemini智能体清晰地暴露了这个问题:
“虽然Gemini 2.5 Pro支持超过100万token的上下文,但如何让智能体有效利用它仍是一个新的研究前沿。在这种智能体设置下,我们观察到,当上下文显著超过10万token时,智能体倾向于从其庞大的历史中重复动作,而不是综合信息制定新的计划。这一现象(尽管是经验性的)突显了长上下文用于检索与用于多步生成式推理之间的重要区别。”
智能体没有利用其预训练知识来开发新策略,反而痴迷于从其冗长的上下文中重复过去的动作。
对于较小的模型,干扰阈值(Distraction Ceiling)要低得多。 Databricks的一项研究发现,Llama 3.1 405B模型以及更小的模型在上下文达到约32K时,回答正确率就开始下降。
如果模型在远未填满上下文窗口之前就开始“行为失常”,那超大窗口的上下文还有什么意义?简而言之:摘要(Summarization)和事实检索(Fact Retrieval)。如果你不做这两件事,请务必警惕所选模型的上下文干扰的长度阈值。
3. 上下文混淆:当无关信息搅局
上下文混淆是指模型在生成低质量响应时,使用了上下文中多余的内容。
曾几何时,似乎人人都在构建MCP。将强大的模型连接到所有你的服务和数据,让它处理所有繁琐任务,这一梦想似乎触手可及。只需把所有工具描述塞进提示词,按下运行键即可。Claude的系统提示词展示了这种方向——其内容大部分是工具定义或使用工具的指令。
但是,即使整合与竞争不会阻挡MCP的步伐,上下文混淆也会成为拦路虎。事实证明,工具过多也是个问题。
Berkeley Function-Calling Leaderboard 是一个评估模型有效响应提示词来使用工具的能力的基准测试。如今已更新到第3版,该排行榜显示,当提示词中包含的工具超过一个时,所有模型的性能都会下降。此外,伯克利团队“设计了与所提供的函数都不相关的场景,……我们期望模型的输出是不调用任何函数。”然而,所有模型都偶尔会调用不相关的工具。
浏览函数调用排行榜,读者会发现随着模型变小,问题会变得更严重:。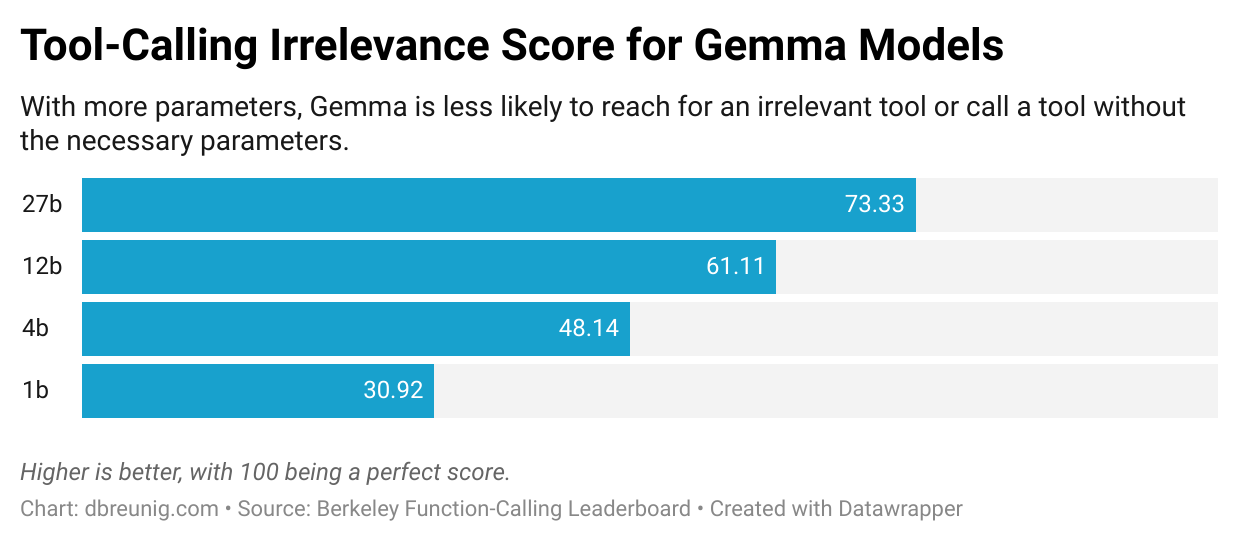
一个引人注目的上下文混淆例子来自近期一篇论文,。该论文评估了小型模型在 GeoEngine 基准测试中的表现,该测试包含 46 种不同的工具。
当研究团队给一个量化的(压缩版)Llama 3.1 8B模型提供包含所有46种工具的query查询时,它失败了,即使上下文远在其16K窗口限制内。然而,当只提供19种工具时,它成功了。
问题的核心在于:一旦你将内容放入上下文,模型就必须关注它。 这可能是不相关的信息或无用的工具定义,但模型会将其考虑在内。大型模型,尤其是推理模型,在忽略或丢弃无关上下文方面确实有所进步,但我们仍不断看到无用信息让智能体陷入困境。长上下文让我们能塞进更多信息,但这种能力伴随着代价。
4. 上下文冲突:当信息自相矛盾
上下文冲突是不断在上下文中累积的新信息/工具与上下文中的其他信息发生冲突。
这是一种问题更大的上下文混淆:这里的“有问题的”上下文不是无关紧要的内容,而是与提示词中的其他信直接冲突。
微软和Salesforce的一个团队在最近的一篇论文中精彩地记录了这种现象。该团队从多个基准测试中提取提示词,并将其信息“分片”(Sharded)到多个提示词中。
想象一下:有时,你可能在ChatGPT或Claude中一口气输入很多的内容,考虑了所有必要的细节之后再提交。而另一些时候,你可能从一个简单的提示词开始,当聊天机器人的回答不尽如人意时,再补充更多细节。微软/Salesforce团队修改了基准提示词,模拟这种多轮交互:
所有左侧提示词的信息都包含在右侧的几条消息中,这些消息会在多轮聊天中展现。
这种“分片”提示词导致了结果急剧恶化,平均下降了39%。研究团队测试了多种模型——OpenAI备受推崇的GPT-4o的得分从98.1骤降到64.1。
这是为什么? 为何信息分阶段收集而非一次性提供时,模型表现反而更差?
答案在于上下文混淆:组装好的上下文包含了整个聊天过程的记录,其中包含了模型在尚未掌握全部信息时对问题做出的早期回应。这些错误的回答依然存在于上下文中,并在模型生成最终答案时对其产生影响。该团队写道:
“我们发现LLM经常在早期的对话中做出假设,并过早尝试生成最终解决方案,之后又过度依赖这些方案。简而言之,我们发现当LLM在对话中‘走错路’时,它们会迷失方向且无法恢复。”
这对智能体开发者来说是个坏消息。 智能体从文档、工具调用以及负责子问题的其他模型中组装上下文。所有这些来自不同来源的上下文,都有可能彼此冲突。此外,当你连接到非自建的MCP工具时,其描述和指令与你提示词的其他部分发生冲突的可能性更大。
结论:长上下文不是万能药
百万级token上下文窗口的到来曾让人感觉这是革命性的。它能够将智能体可能需要的所有东西一股脑塞进提示词,激发了人们对超级智能助手的憧憬——它能访问任何文档、连接所有工具、拥有完美记忆。
但正如我们所看到的,更大的上下文创造了新的失败模式。 上下文污染会嵌入错误并随时间发酵;上下文干扰导致智能体过度依赖上下文、重复过去动作而非向前推进;上下文混淆导致使用无关的工具或文档;上下文冲突则制造内部矛盾,扰乱推理进程。
这些故障对智能体的打击最为沉重,因为智能体恰恰运行在那些上下文极易膨胀的场景中:从多个来源收集信息、进行连续工具调用、参与多轮推理、积累大量历史记录。
展望:解决方案何在?
幸运的是,存在解决方案!在接下来的文章中,我们将探讨缓解或避免这些问题的技术,从动态加载工具的方法,到创建“上下文隔离区”(Context Quarantines)的策略。
敬请阅读后续文章: “How to Fix Your Context“
脚注:
Gemini 2.5 和 GPT-4.1 拥有 100 万token的上下文窗口,足以轻松容纳《无限玩笑 Infinite Jest 》这样的大部头,还有大量剩余空间。
Gemini 文档中的“长文本”部分很好地总结了这种乐观情绪。 ↩
事实上,在上述引用的 Databricks 研究中,模型在处理长上下文时一个常见的失败模式是:它们会返回对提供上下文的摘要,却忽略提示词中包含的任何指令。
如果你参考这个排行榜,请关注“Live (AST)”列。这些指标使用了由企业贡献到产品中的真实世界工具定义,“避免了数据集污染和带有偏见的基准测试的缺点”。