
前言
尽管”上下文工程”(Context Engineering)背后的原理并不新鲜并非全新概念(译者注:所以也有很多人对这个新名词嗤之以鼻,觉得是炒作,不过回顾历史,所有新技术新思想都不是无根之木,都是站在先前的技术之上的),但这个术语是一个有用的抽象概念,它能帮助我们思考在构建高效的AI智能体时所满脸林的最紧迫的挑战。因此,我们来分解一下。本文将涵盖三个方面的内容:上下文工程的定义、它与”提示工程”的区别,以及如何运用LlamaIndex和LlamaCloud来设计符合上下文工程原则的智能体系统。
什么是上下文工程?
AI智能体需要获取与任务相关的上下文才能合理地执行任务。虽然这一点我们早就知道了,但在AI技术快速迭代的背景下,我们需要不断提出新的抽象概念来让我们能够用一种易于理解的名词来思考最佳实践和新方法。正如Andrey Karpathy(译者注:OpenAI前科学家)的精辟总结:
People associate prompts with short task descriptions you’d give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step.
人们通常将”提示词”等同于日常使用大模型时的简短任务描述,而在工业级大模型应用中,上下文工程是一门精妙的艺术与科学——它专注于如何用最精准的恰到好处的信息为下一步要执行的操作填充上下文窗口。
与聚焦于前端提供正确指令设计的”提示工程”不同,”上下文工程”更强调从各种来源筛选最相关的信息来填充LLM的上下文窗口。
这自然引出一个疑问:”这不就是RAG(检索增强生成)吗?听起来它更像专注于检索”, 有这个疑问是对的。确实,上下文工程包含检索环节,丹又不仅仅是检索步骤,它的内涵更广——它要求我们将上下文窗口视为需要精心策划的东西,像策展人般精心设计信息组合,并充粉考虑它的限制(字面意思商的限制,即上下文窗口的限制),。
上下文的构成要素
在撰写这篇博客之前,我们阅读了Philipp Schmid的(The New Skill in AI is Not Prompting, It’s Context Engineering”)[https://www.philschmid.de/context-engineering]《AI领域的新技能不是提示工程,而是上下文工程》,他在其中出色地剖析了AI智能体或LLM的上下文构成要素,因此,我们参考它的内容进行了补充,上下文可以具体分为以下内容:
- 系统提示/指令(system prompt/instruction):为智能体设定场景,说明我们希望它执行什么任务
- 用户输入:可以是任何内容,包括用户问题或完成某项任务的要求。
- 短期记忆/对话历史:为LLM提供关于当前聊天的上下文,保持对话连续性。
- 长期记忆:可存储和检索的长期聊天历史信息或其他相关数据
- 知识库检索信息:可以来自向量数据库搜索,也可以来自API调用、MCP工具或其他来源所检索的相关信息。
- 工具及其定义:为 LLM 提供额外上下文,说明其可调用的工具
- 工具响应:将工具运行的响应结果作为额外上下文提供给LLM进行处理。
- 结构化输出:既可以用来指定希望从LLM获取何种信息的输出格式,也可以反过来,为特定任务提供精炼、结构化的信息作为上下文。
- 全局状态/全局上下文:这与使用LlamaIndex构建的智能体尤其相关,它允许我们将工作流上下文(workflow Context)用作一种草稿板(scratchpad),可以在智能体步骤之间存储和检索全局信息。
这些元素的有机组合构成了当今几乎所有智能体AI应用的中底层LLM的上下文。,这引出了我们的核心观点:仔细思考选择上述哪些内容应该构成您的智能体的上下文以及以何种方式将这些内容组织起来,这正是上下文工程的核心命题。那么,让我们来看一些可能需要考虑上下文策略的情况,以及如何使用 LlamaIndex 和 LlamaCloud 实现这些策略。
上下文工程的技术和策略
再看一眼前面提到的上下文要素列表,读者就会注意到有很多东西可以构成我们的上下文,这意味着我们面临着两大挑战:选择正确的上下文,以及使其适配有限的上下文窗口。虽然我意识到这个列表可能会变得更长,但让我们看看在为智能体设计正确上下文时,一些会首先出现在脑海中的架构选择:
1. 知识库与工具选择
当我们想到 RAG 时,我们主要指的是设计那种在单个知识库(通常是向量存储)上进行问答的 AI 应用。但是,对于当今的大多数智能体应用来说,情况已不再如此。我们现在看到的应用往往需要访问多个知识库,可能还需要一些能够返回更多上下文或执行特定任务的工具。
然而,在我们从知识库或工具检索额外上下文之前,LLM首先拥有的上下文是关于可使用的工具或知识库本身的信息。这种上下文使我们能够确保我们的智能体AI应用程序选择正确的资源。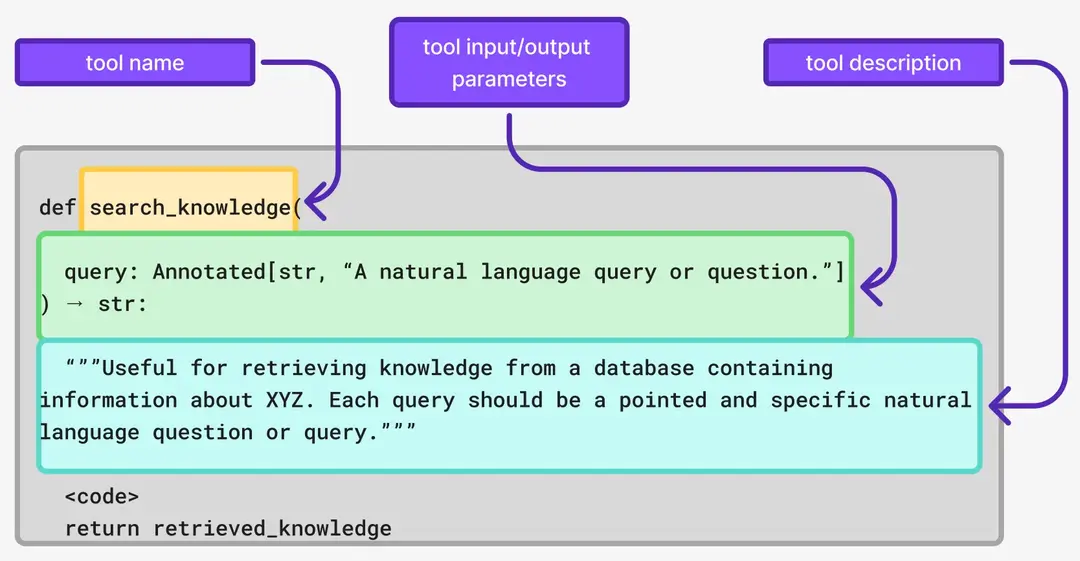
2. 上下文排序与压缩
在上下文工程中,另一个重要的考虑因素是上下文限制.受限于上下文窗口大小,我们发展出多种优化技术实现方案:
上下文摘要:即在完成给定的检索步骤之后,我们在将结果添加到LLM上下文之前信生成摘要。
在其他一些情况下,重要的不仅是上下文的内容,还包括其出现的顺序。考虑一个场景,我们不仅需要检索数据,而且信息的日期也高度相关。在这种情况下,加一个排序环节,让LLM接收到最相关的信息(按顺序排列),也会非常有效。
1 | def search_knowledge(query: Annotated[str, "自然语言查询问题"]) -> str: |
3. 长期记忆存储和检索方案
如果我们有一个需要与 LLM 进行长期不断地对话的应用,历史记录本身就是上下文。LlamaIndex提供和实现了多种长期记忆模块。出于同样原因,同时也提供了一个可扩展的基础记忆块(Base Memory Block ),以实现您可能拥有的任何独特记忆需求。
VectorMemoryBlock:一个将聊天消息批次存储到向量数据库并从中检索的记忆块。
FactExtractionMemoryBlock:一个从聊天历史中提取事实的记忆块。
StaticMemoryBlock:一个存储静态信息片段的记忆块。
每次我们与智能体进行迭代时,如果在某些使用场景中,长期记忆很重要,那么智能体就需要在决定下一步最佳行动之前从中检索额外的上下文。这使得决定需要什么样的长期记忆以及它应该返回多少上下文成为一个相当重要的决策。在LlamaIndex中,我们已经实现让您可以自由组合使用上述长期记忆块。
4. 结构化信息运用
我们在创建智能体AI系统时常看到的一个错误是,经常在不必要的时候提供所有上下文;当不需要时,它可能会挤占上下文限制的空间。
。结构化输出(Structured outputs)是我近年来最喜欢的LLM功能之一,原因就在于此。它们对给LLM提供最相关的上下文可以产生重大影响。而且这种影响是双向的:
请求的结构:这是一个我们可以提供给LLM的模式(schema),要求其输出与该模式匹配。 (译注:通过schema限定LLM的输出格式)
作为附加上下文提供的结构化数据:这是一种我们可以向LLM提供相关上下文的方式,而同时避免包含额外的、不必要的上下文。(译注:将复杂信息提炼为结构化数据输入)
LlamaExtract是LlamaCloud的一个工具,它允许您利用LLM的结构化输出功能,从复杂冗长的文件和来源中提取最相关的数据。提取后,这些结构化输出可以用作下游智能体应用程序的精简上下文。
5. 工作流工程
上下文工程侧重于优化单次LLM调用的信息输入,而工作流工程则从宏观视角设计和组合LLM调用与非LLM步骤的执行序列来可靠地完成某项工作。最终,这也是我们能够优化上下文。LlamaIndex Workflows 提供了一个事件驱动的框架,它支持:
- 明确定义步骤序列:对应于完成复杂工作所需的确切任务流程。
- 策略性地控制上下文:精确决定何时使用LLM,何时使用确定性逻辑或外部工具。
- 确保可靠性:内置验证、错误处理和回退机制,这是简单智能体所无法提供的。
- 针对特定结果进行优化:创建专门的流程,始终如一地提供您的业务所需的结果
从上下文工程的角度来看,工作流至关重要,因为它可以防止上下文过载。与其将所有内容都塞进一个 LLM 调用中并寄希望于最好的结果,不如将复杂任务分解为聚焦的步骤,每个步骤都有自己优化的上下文窗口。
这里的战略洞察在于,每个 AI 构建最终都在构建专业化的工作流——无论他们是否意识到这一点。文档处理工作流、客户支持工作流、编码工作流——这些都是构建可真正落地的AI应用的基础模块。
这种分步执行策略能有效避免单次上下文过载,使每个步骤都聚焦于优化后的上下文窗口。需要强调的是,所有AI构建本质上都是在创建专业化工作流——无论是文档处理、客户支持还是代码生成场景。