论文链接:https://arxiv.org/abs/2310.11511
项目主页:https://selfrag.github.io/
问题:事实不准确的通用大语言模型
尽管大型语言模型(LLMs)具有非凡的能力,但由于它们完全依赖于其封装的参数知识,因此经常会产生包含不准确事实的回复。它们经常会产生幻觉,尤其是在长尾情况下,它们的知识会过时,并且缺乏明确的来源或引用。
RAG是灵丹妙药吗?
检索增强生成(RAG)是一种通过检索相关知识来增强 LM 的方法,可以减少此类问题,并在QA问答等知识密集型任务中显示出有效性。然而,不加区分地检索和纳入固定数量的检索段落,而不管检索是否必要或段落是否相关,会降低 LM 的通用性,或导致生成没有帮助的响应。此外,也无法保证保证生成的内容一定来源于引用的证据。
什么是 Self-RAG?
自我反思(Self-Reflective)检索增强生成(Self-RAG)是一个通过检索和自我反思提高 LM 生成质量和真实性的新框架。这个框架会训练一个 LM,这个 LM 可按需检索信息(例如,可在生成过程中多次检索,或完全跳过检索),生成内容,并使用特殊标记(称为反思标记reflection token)生对检索到的段落及其自己生成的内容进行反思。生成反思标记使 LM 在推理阶段具有可控性,使其能够根据不同的任务调整自己的行为以符合要求。
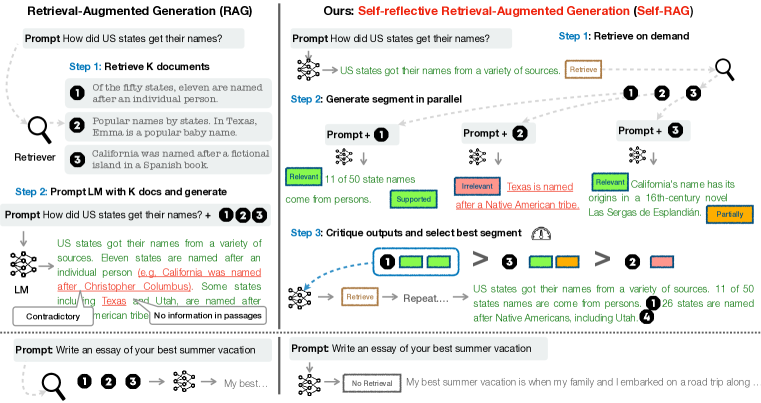
图1
以参加开卷考试为例,我们通常有两种策略:
- 方法1:对于熟悉的题目,快速作答;对于不熟悉的题目,打开参考书查找,快速找到相关部分,在脑海中进行分类、归纳,然后在试卷上作答。
- 方法 2:每个题目都要参考书目。找到相关章节,在头脑中进行整理和归纳,然后在试卷上写下你的答案。
显然,方法 1 是首选方法。方法 2 可能会耗费时间,并有可能引入不相关或错误的信息,这可能会导致混乱和错误,甚至是在你原本理解的领域。方法 2 体现了传统的 RAG 过程,而方法 1 则代表了Self-RAG 过程。
具体来说,在每个片段(如句子),Self-RAG 可以:
检索(Retrieve):Self-RAG 首先解码出一个检索标记(retrieval token),以评估检索的有效性(对于后续内容生成,检索是否有帮助)。如果需要检索,LM 会调用外部检索模块,利用输入查询和上一次生成的信息,查找最相关的文档。
生成(Generate):如果不需要检索,模型就会像普通的 LM那样预测下一个输出片段。如果需要检索,模型会生成一个评估标记( critique token),评估检索到的文档是否相关,然后根据检索到的段落生成后续内容。
评估(Critique):如果需要检索,模型会进一步评估段落内容是否支持生成的结果。此外,在最后还会生成一个新的评估标记( critique token)来评估回复的整体效用和水平。
形式上,给定输入x 后,我们训练 ℳ 依次生成由多个片段 y=[y1,…,yT] 组成的文本输出 y ,其中 ,yT 表示第T个片段的标记序列。 一个片段一般对应一个句子。这与之前的大模型并没有本质的区别。
下面列出的是在训练和推理过程中用到的几种不同类型的反思标记(reflection token)。
| 标记类型 | 输入 | 输出 | 定义 |
|---|---|---|---|
| Retrieve | xlx,y | yes, no, continue | 根据输入的问题x 或者问题x以及前面生成的内容y 决定是否使用检索器R来进行检索 continue的值表示模型可以继续使用之前检索到的证据 |
| ISREL | x,d | relevant,irrelevant | 检索到的文档d是否提供了有助于解决问题x的有关信息 |
| ISSUP | x,d,y | fully supported, partially supported, no support | 生成的内容y中所有需要进一步核实的信息是否都在文档d中有相应的支持。 |
| ISUSE | x,y | 5, 4, 3, 2,1 | 对于问题x,生成的答复内容y是有用的回复 |
Self-RAG中共有4种反思标记(reflection token),大致分为Retrieve和Critique两大类。其中Critique标记又分为IsREL、IsSUP、IsUSE三小类,其中粗体表示某类token最期望的取值。
Self-RAG 有多厉害?
实验表明,Self-RAG(7B 和 13B 参数)在各种任务中的表现明显优于最先进的 LLMs 和检索增强模型。具体来说,在开放域QA问答、推理和事实验证任务上,Self-RAG 的表现优于 ChatGPT 和检索增强的 Llama2-chat,而且与这些模型相比,Self-RAG在改善长篇内容生成的真实性和引文准确性方面也有显著提升。
Self-RAG 推理过程
推理概述

算法1
图 1 和算法 1 展示了推理中的 Self-Rag 概述。
对于每一个 x和 已经生成的内容y<t ,模型都会解码一个检索标记(retrieval token),以评估检索的有效性。如果不需要检索,模型就会像标准 LM 那样预测下一个输出片段。如果需要检索,模型就会生成:
- 1、一个评论标记来评估检索段落的相关性
- 2、下一个响应片段
- 3、一个评论标记来评估响应片段中的信息是否得到所检索的段落的支持。
- 4、一个新的评论标记会评估回复的整体有效性。
为了生成输出片段,Self-Rag 会并行处理检索到的段落,并使用自己生成的反思标记(reflection token)对生成的任务输出执行宽松约束(soft constraints )或严格控制(hard control)(算法 1)。
- 例如,在图 1(右图)中,由于 d2 与用户问题不相关,而 d3 的输出结果只能部分内容得到文档支持,而 d1 的输出结果是能得到文档完全支持的,因此在第一个时间步骤中选择了检索到的段落d1 。
带检索标记( retrieval token)和阈值的的自适应检索
先前的工作通常在生成过程中固定时间检索段落(例如,只在开始时检索,或者每隔 k 个令牌检索一次),难以在质量和效率之间取得平衡。在 Self-RAG 学习生成检索标记以灵活检索的同时,人们还可以利用检索标记的token概率,根据其软约束条件改变检索频率。
带阈值的自适应检索
Self-Rag 通过预测检索标记(Retrive token)来动态决定何时检索文本段落。此外,该框架还允许设置阈值。具体来说,如果在所有Retrive输出标记中产生=Yes标记的概率超过了指定的阈值,我们就会触发检索。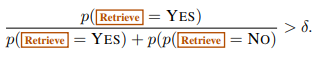
根据上述策略,Self-RAG可以在推理阶段进行检索控制,从而使其行为适应不同的任务要求。
- 对于事实准确性要求高的任务,目标则是让模型更频繁地检索段落,以确保输出结果与现有证据密切吻合。
- 在开放性较强的任务中,如撰写个人经历文章,重点则转向减少检索次数,优先考虑整体创造性或实用性得分。
带有评估标记(critique token)的树状解码
Self-RAG 引入了多个细粒度的评估标记,对生成内容的质量从不同方面(如证据支持性、完整性)进行评估。我们使用理想评估标记概率的线性内插法进行分段级波束搜索( beam search),以在每个时间段内确定 K 个最佳连续句。
在每个分段步骤 t 中,当需要根据严格条件或宽松条件(soft condition)进行检索时, ℛ 会检索K 个段落,生成器 ℳ 会并行处理每个段落,并输出K 个不同的候选后续片段。我们进行分段级波束搜索(beam search)(beam size=B ),以获得每个时间戳t的前B 段连续序列,并在生成结束时返回最佳序列。每个片段 yt 相对于段落d的得分会用评估者得分 𝒮 更新,该得分是每种标记类型的归一化概率的线性加权和。对于每个评估标记组 G (例如IsREL),我们将其在时间戳 t的得分记为 StG ,并按如下方式计算段落得分:
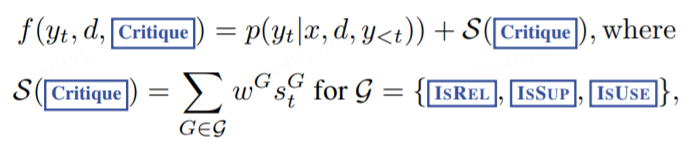
在时间步t时,G的得分为 ,代表最期望的反思标记 相对有 NG个不同取值的评估标记类型 G的概率值。公式中的 wG权重 是超参数,可以在推理时进行调整 以便在测试时实现自定义行为。为了确保结果 y得到大部分证据的支持,可给IsSUP较高的权重,而给其他标记较低的权重,这是软性控制行为。通过在解码环节设置评估器critique,我们也可以施加硬性约束。我们可以不使用公式中的软奖励函数,而是在模型生成不良标记(比如IsSUP=No support)时,就明确过滤掉一个候选的后续片段。在 RLHF(Touvron 等人,2023 年;Wu 等人,2023 年)中已经对平衡多种偏好之间的权衡进行了研究,这通常需要通过训练来改变模型的行为。Self-RAG 不需要额外的训练就能定制 LM。
run_long_form_static.py 文件中 call_model_beam_batch函数的流程图
输入是prompt 以及一组检索文档数组
输出是两个数组:
- final_prediction:最终生成的结果数组
- result 包含详细的中间信息的对象,包含的属性的值都是数组(每个有效结果对应里面一条记录),属性有:
- final_prediction”: 与final_prediction相同
- “splitted_sentences”: self-rag是一句一句生成的,所以是与final_prediction中的字符串记录合并前的大模型生成的结果,
- “original_splitted_sentences”: 包含了原始的反思令牌信息的句子数组的数组,
- “best_selections”: beam search后的自底向上的树的路径
- “ctxs”: 生成句子所使用的检索段落信息
- “prediction_tree”: beam search中的所有节点的信息

run_step_generation_batch函数的流程图
输入是一个prompt 以及一个paragraphs数组
输出:和paragraphs数组的内容相对应的三个数组,
- preds: 根据每个检索到的段落由大模型对应生成的结果(包含反思标记)数组
- scores:对生成结果根据各个反思标记的概率分布进行打分的数组
- overall_scores;包含详细打分以及中间数据的数组
{“final_score”、”relevance_score”、”ground_score”、”utility_score”、”relevance_score_dict”、 “grd_score_dict”、”ut_score_dict”}

Self-RAG执行效果
1 | # Import necessary libraries |
执行结果如下: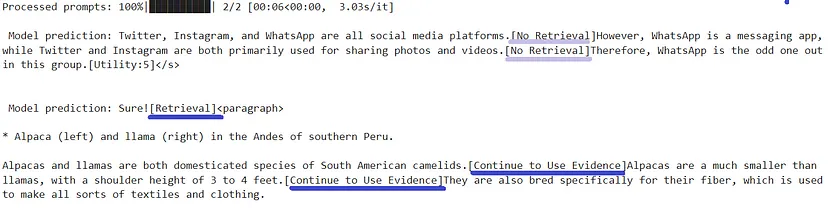
执行了两个查询,在第一个查询中,Self-RAG 直接生成响应而不检索信息,因为这是不必要的。在第二个查询中,Self-RAG 显示 [Retrieve] 标记,因为问题需要更多事实信息。
1 | # 用户问题需要检索并将检索文档通过format_prompt添加到prompt中 |

训练过程
训练概述
Self-RAG可使一个LM 生成带有反思标记(reflection token)的文本,方法是扩展模型词汇(即原始词汇加上反思标记(reflection token)),并以标准的下一个token预测为任务目标进行训练。
Self-RAG 训练包括两种模型:Critic和Generator。
具体来说,在一个经过设计的语料库上训练生成器模型 ℳ ,该语料库中检索器 ℛ 检索到的段落和由评估模型 𝒞 预测的反思标记在语料中交替出现(参见后面的语料示例)。
我们先训练一个评估模型𝒞 生成反思标记,用于评估检索到的段落和给定任务输出的文本的质量。利用评估模型𝒞,通过在离线任务输出结果中插入反思标记来更新训练语料库。随后,我们使用传统的 LM token预测作为任务目标来训练最终生成模型( ℳ ),使 ℳ 能够在推理时不依赖评估模型而自行生成反思标记。
- 步骤 1 创建评估数据:通过提示 GPT-4 生成反思标记来生成 Critic 训练数据。
- 步骤 2 Critic模型训练:在合成数据集上训练 Critic 模型。
- 步骤 3 Generator数据创建:使用 Critic 和 Retriever 生成生成器训练数据。
- 步骤 4 Generator模型训练:在 RAG 数据集上训练生成器,包括教授模型何时检索或不检索的特殊标记。
生成模型的训练语料示例
Input: Identify the two types of computer memory. (from gpt4_alpaca)
Output: [==Retrieve===Yes] <p> Computer memory Computer memory – In computing, memory refers to the computer hardware integrated circuits that store information for immediate use in a computer; it is synonymous with the term “primary storage”. Computer memory operates at a high speed, for example random-access memory (RAM), as a distinction from storage that provides slow-to-access information but offers higher capacities. If needed, contents of the computer memory can be transferred to secondary storage; a very common way of doing this is through a memory management technique called “virtual memory”. An archaic synonym for memory is store. The term “memory”, meaning “primary storage” or “main memory”, is<p>[ ==IsREL===Relevant]Primary memory, also known as main memory, is the memory that the computer can directly access and manipulate. [==IsSUP===Fully Supported] [==Retrieve===Yes]<p>Computer memory–often associated with addressable semiconductor memory, i.e. integrated circuits consisting of silicon-based transistors, used for example as primary storage but also other purposes in computers and other digital electronic devices. There are two main kinds of semiconductor memory, volatile and non-volatile. Examples of non-volatile memory are flash memory (used as secondary memory) and ROM, PROM, EPROM and EEPROM memory (used for storing firmware such as BIOS). Examples of volatile memory are primary storage, which is typically dynamic random-access memory (DRAM), and fast CPU cache memory, which is typically static random-access memory (SRAM) that is fast but energy-consuming, offering lower memory<p>[ ==IsREL== =Relevant]Primary memory can be accessed quickly, but it is volatile, meaning that the data is lost if the power is turned off.[==IsSUP== =Partially Supported]…[==IsUSE==:5
Self-RAG 训练
训练评估者模型 𝒞
评估模型的数据收集
对每个片段的反思标记进行人工标注的成本很高。GPT-4等最先进的 LLM 可以有效地生成此类内容。然而,依赖这种专有的 LM 会提高 API 成本,降低可重复性。所以通过提示 GPT-4 生成反思标记来创建监督数据,然后将其知识提炼为内部 𝒞 。
对于每组反思标记,从原始训练数据中随机抽取实例: {Xsample,Ysample}∼{X,Y} 。如表 1 所示,不同的反思令牌组有各自的定义和输入,因此对这些令牌使用不同的指令提示来生成。在此,我们以 GPT-4 为例。我们向 GPT-4 发送了一条特定类型的指令(Given an instruction, make a judgment on whether finding some external documents from the web helps to generate a better response.)(”给定指令,请判断从网络上查找一些外部文档是否有助于生成更好的回复。”),然后通过小样本示范 I、 原始任务输入 x 和输出 y 来预测一个合适的反思标记文本:p( r | I, x, y ) 。
人工评估结果表明,GPT-4 的反思标记预测与人工评估结果具有很高的一致性。我们为每种类型收集了 4k-20k 个有监督的训练数据,并将它们组合起来形成 𝒞 的训练数据。
评估模型学习
在收集到训练数据𝒟critic,之后,我们用预先训练好的 LM 对 𝒞 进行初始化,并使用标准的条件语言建模目标(最大化可能性)对𝒟critic,进行训练:
虽然初始模型可以是任何预先训练好的 LM,但我们使用了与生成 LM 相同的 LM(即 Llama 2-7B;Touvron 等人,2023 年)进行 𝒞 初始化。在大多数反思标记类别上,评估模型与基于 GPT-4 的预测结果的一致性超过了 90%(附录表 4)。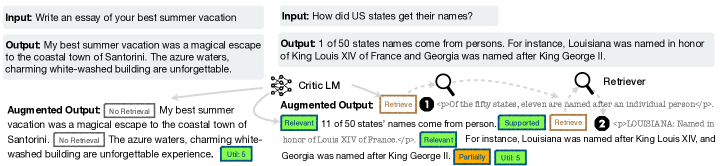
左边的例子不需要检索,而右边的例子需要检索,因此插入了段落。
训练生成模型
为生成器收集数据
给定一个输入-输出对 (x,y) ,我们使用检索器和评估模型扩充原始输出 y,以创建精确模拟 Self-RAG推理过程的监督数据。对于每个段落 yt∈ y,我们运行 𝒞 来评估通过检索来获取额外的段落是否有助于增强生成的内容。如果需要检索,则添加检索特殊标记 Retrive =Yes,然后 ℛ 检索前K个 段落 𝐃 。对于每个段落, 𝒞 会进一步评估该段落是否阈输入x相关,并预测IsRel。.如果段落相关, 𝒞 会进一步评估该段落是否支持模型生成的结果,并预测IsSup .在检索到的段落或生成的内容之后,会附加评估标记IsRel 和 IsUse。在输出的末尾, y(或 yT )、 𝒞 预测总体的有用性标记IsUSE ,并将带有反思标记和原始输入对的增强输出添加到 𝒟gen 中。
生成器学习
我们使用标准的下一个标记目标,在添加了反射标记 𝒟gen 的语料库上训练生成器模型 ℳ :
与 𝒞 训练(公式 1)不同, ℳ 学习预测目标输出以及反思标记。在训练过程中,我们会屏蔽掉检索到的文本块(图 2 中用 <p> 和 </p> 包起来),以计算损失,并用一组反思标记 {Critique , Retrieve} 来扩展原始词汇 𝒱 。

SELF-RAG训练
参考实现:
原始实现代码
langchain版Self-RAG
该代码只是参考了Self-RAG的一些思想(Retrive节点检索文档后由Grade节点进行打分判断是否相关,利用相关文档通过Generate节点生成结果然后利用大模型检测参考文档是否支持生成的结果(也就是是否有幻觉(Hallucination))以及利用大模型检查生成结果是否回答了原始问题(Answers question)也就是是否有用),并不是严格的Self-RAG实现代码。
这个实现也是体现RAG Flow,体现 RAG 的 “流程工程(flow engineering) “的例子,包括特定的决策点(如文档分级)和循环(如重试检索)。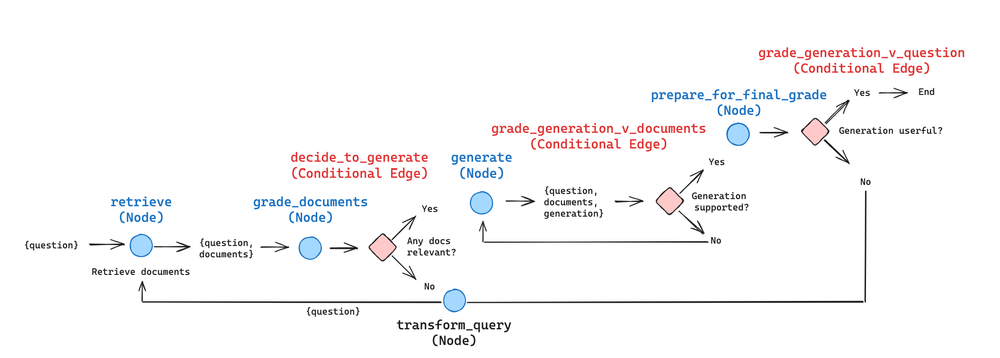
llamaindex版Self-RAG
1 | import os |
所以其中的重点是 SelfRAGQueryEngine 这个自定义类的query方法的实现逻辑